Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems
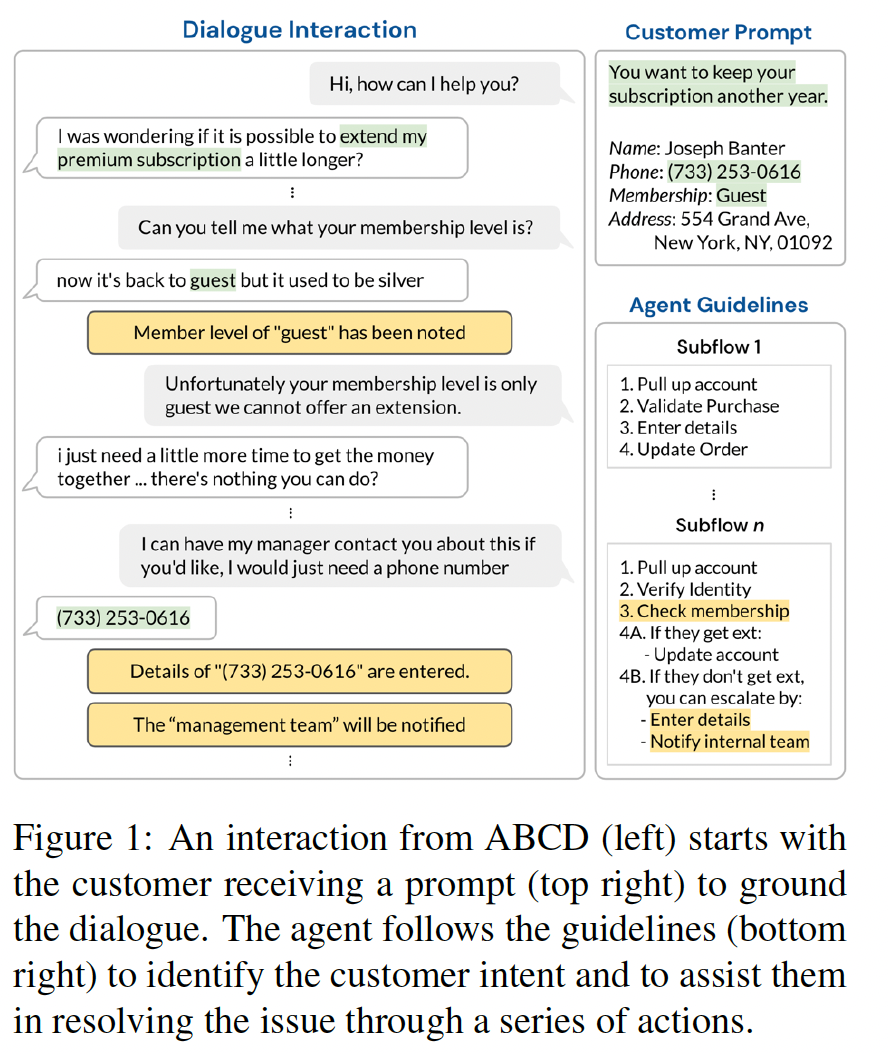
Existing goal-oriented dialogue datasets focus mainly on identifying slots and values. However, customer support interactions in reality often involve agents following multi-step procedures derived from explicitly-defined company policies as well. To study customer service dialogue systems in more realistic settings, we introduce the Action-Based Conversations Dataset (ABCD), a fully-labeled dataset with over 10K human-to-human dialogues containing 55 distinct user intents requiring unique sequences of actions constrained by policies to achieve task success. We propose two additional dialog tasks, Action State Tracking and Cascading Dialogue Success, and establish a series of baselines involving large-scale, pre-trained language models on this dataset. Empirical results demonstrate that while more sophisticated networks outperform simpler models, a considerable gap (50.8% absolute accuracy) still exists to reach human-level performance on ABCD. 1
Introduction. The broad adoption of virtual assistants and customer service chatbots in recent years has been driven in no small part by the usefulness of these tools, whereby actions are taken on behalf of the user to accomplish their desired targets (Amazon, 2019; Google, 2019). Research into taskoriented dialogue has concurrently made tremendous progress on natural language understanding of user needs (Wu et al., 2019; Rastogi et al., 2020b; Liang et al., 2020). However, selecting actions in real life requires not only obeying user requests, but also following practical policy limitations which may be at odds with those requests. For example, while a user may ask for a refund on their purchase, an agent should only honor such a request if it is valid with regards to the store’s return policy. Described in actions, before an agent can [Offer Refund], they must first [Validate Purchase]. Furthermore, resolving customer issues often concerns multiple actions completed in succession with a specific order since prior steps may influence future decision states.
Discussion / Conclusion. In conclusion, we have presented ABCD which includes over 10K dialogues that incorporate procedural, dual-constrained actions. Additionally, we established a scalable method for collecting live human conversations with unequal partners. We found that pre-trained models perform decent on Action State Tracking, but there is a large gap between humans agents and the top systems for Cascading Dialogue Success. We plan to incorporate GPT-related models (Hosseini-Asl et al., 2020), as alternate forms of preprocessing have shown promise in other NLP tasks. Other techniques could also be used to incorporate speaker info, action semantics and other meta-data. Wholly new systems that attend to the Agent Guidelines in a fully differentiable manner are also worth exploring. By grounding dialogues to in-depth scenarios with explicit policies, we hope to have pushed towards a better understanding of dialogue success.