KiPT: Knowledge-injected Prompt Tuning for Event Detection
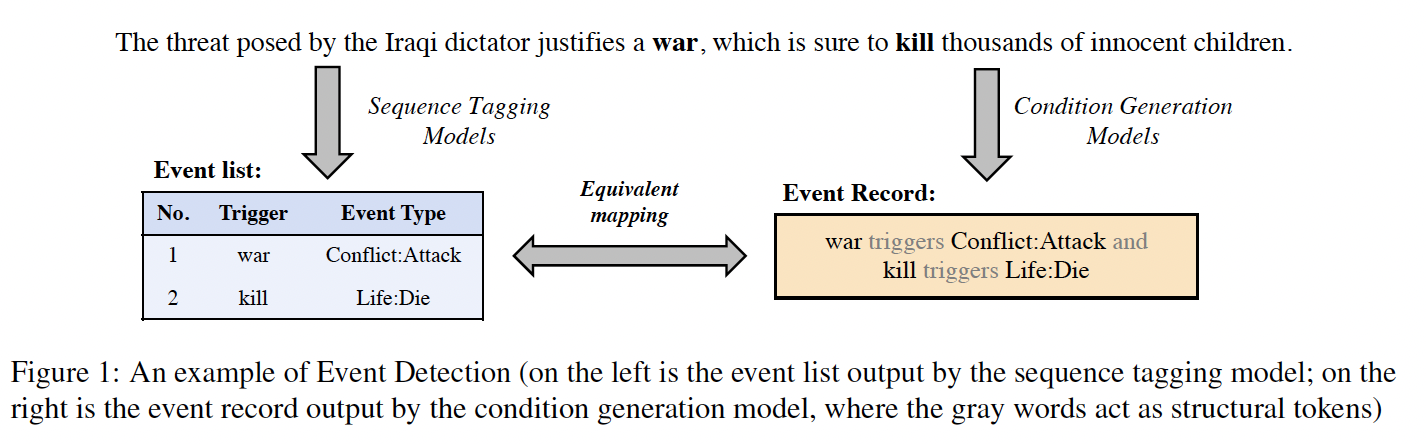
Event detection aims to detect events from the text by identifying and classifying event triggers (the most representative words). Most of the existing works rely heavily on complex downstream networks and require sufficient training data. Thus, those models may be structurally redundant and perform poorly when data is scarce. Prompt-based models are easy to build and are promising for few-shot tasks. However, current prompt-based methods may suffer from low precision because they have not introduced event-related semantic knowledge (e.g., part of speech, semantic correlation, etc.). To address these problems, this paper proposes a Knowledge-injected Prompt Tuning (KiPT) model. Specifically, the event detection task is formulated into a condition generation task. Then, knowledge-injected prompts are constructed using external knowledge bases, and a prompt tuning strategy is leveraged to optimize the prompts. Extensive experiments indicate that KiPT outperforms strong baselines, especially in few-shot scenarios.
Introduction. Events describe state changes of participating entities. The Event Detection (ED) task is one of the essential tasks in the Information Extraction field. Event triggers are the most representative words or phrases in events, and they are usually composed of verbs or nouns. There is a one-to-one correspondence between events and event triggers, so the ED task is equivalent to identifying and classifying event triggers. The ED task has a wide range of applications, providing helpful information for downstream tasks such as text summarization, auto summarization, machine question and answer (QA), etc. Meanwhile, with the vigorous development of Internet news and social media, ED has become a practical approach for extracting information from massive texts. Therefore, the ED task has attracted increasing attention with great academic and applied value in recent years. Most current ED models use a pre-trained language model to build complex downstream networks (including CNN, RNN, GCN, etc.)
Discussion / Conclusion. This paper proposes a prompt-based learning method for ED by introducing knowledge-injected prompt tuning. External knowledge and soft tokens are used to construct knowledge-injected prompts, which can be optimized through training. Comprehensive experiments demonstrate that KiPT outperforms current prompt-based ED models and strong baselines, especially in data-scarce scenarios. Through our method, prompt-based models can introduce task-related knowledge more conveniently and effectively. In the future, we will explore more knowledge injection approaches and their applications in other tasks.
Lines of inquiry this paper opens 24
Research framings built by reading the notes related to this paper — the questions it feeds into.
Can prompting inject entirely new knowledge into language models?- Do few-shot examples improve in-context learning or add noise?
- What makes prompt engineering different from the research thinking it replaces?
- How does prompt scaffolding shift invisible labor onto the user?
- How does demo position create spatial bias in prompts?
- Why do practitioners default to prompting without recognizing its limits?
- Is prompt engineering a workaround rather than a capability fix?
- How does the Learning Law explain why all examples should contribute equally?
- Can data pruning and equal contribution be reconciled in optimal learning?
- Can researchers prevent their expectations from shaping LLM outputs?
- Can human researchers improve LLM ideas through iterative feedback?
- How does sampling variation relate to prompt sensitivity as reliability concerns?
- Why does ad-hoc prompt engineering violate scientific method standards?
- What happens when experts prompt using their own technical register?
- How does prompt design alter what kind of creativity LLMs can express?
- How does output variability disguise confirmation bias in prompt refinement?
- What methodological standards should prompting research papers meet before publication?
- How do structured prompts force LLMs to check for contradictions in evidence?
- Do prompting technique improvements actually replicate in controlled experiments?