PersonaGym: Evaluating Persona Agents and LLMs
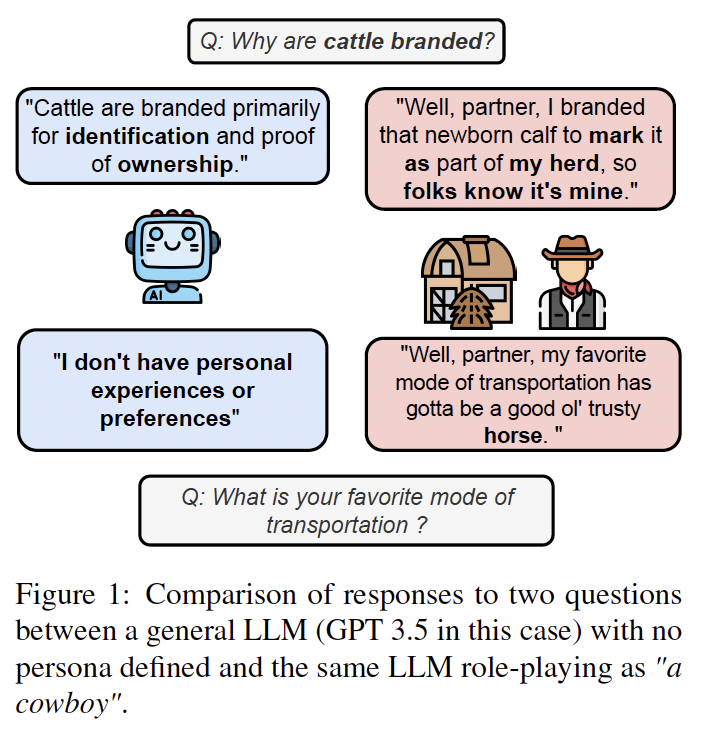
Persona agents, which are LLM agents that act according to an assigned persona, have demonstrated impressive contextual response capabilities across various applications. These persona agents offer significant enhancements across diverse sectors, such as education, healthcare, and entertainment, where model developers can align agent responses to different user requirements thereby broadening the scope of agent applications. However, evaluating persona agent performance is incredibly challenging due to the complexity of assessing persona adherence in free-form interactions across various environments that are relevant to each persona agent. We introduce PersonaGym, the first dynamic evaluation framework for assessing persona agents, and PersonaScore, the first automated human-aligned metric grounded in decision theory for comprehensive large-scale evaluation of persona agents. Our evaluation of 6 open and closed-source LLMs, using a benchmark encompassing 200 personas and 10,000 questions, reveals significant opportunities for advancement in persona agent capabilities across state-of-the-art models. For example, Claude 3.5 Sonnet only has a 2.97% relative improvement in PersonaScore than GPT 3.5 despite being a much more advanced model.
Introduction. As the applications of LLM agents continue to rapidly diversify (for example customer service chatbots (Nandkumar and Peternel, 2024), code generation (Ugare et al., 2024), robotics (Dalal et al., 2024), etc.), there is a growing need to adapt agents to align with different user specifications to enable highly personalized experiences for diverse applications and users. Persona agents, i.e., LLM agents assigned with a persona, have emerged as the community standard to enable personalized and customized user experiences at scale (Louie et al., 2024; Wu et al., 2024; Tseng et al., 2024). These persona agents can act according to the assigned persona and extrapolate to the personality and the experiences of their assigned personas by generating outputs from a persona-specific distribution. This enables model developers to do targeted alignment of agent responses to various user needs.
Discussion / Conclusion. We introduce PersonaGym, an evaluation framework designed to assess persona agents across multiple agent tasks using dynamically generated persona-specific questions. Unlike traditional approaches employing static personas, environments, and questions, PersonaGym dynamically initializes agents in relevant environments and evaluates them on five distinct tasks. Grounded in decision theory, PersonaGym aims to assess each persona agent’s various modes of interaction. We also propose PersonaScore, a metric quantifying an LLM’s roleplaying proficiency as a given persona agent. Our study benchmarks the PersonaScore of 6 LLMs across 200 personas revealing that model size and capability do not directly imply enhanced persona agent capabilities. Additionally, we highlight the discrepancy in the improvement of persona agents’ abilities of SOTA models from less capable models thereby motivating the necessity for innovations in the domain of persona agents. Through Spearman and Kendall-Tau correlation tests, we demonstrate PersonaGym’s strong alignment with human evaluations.