PRewrite: Prompt Rewriting with Reinforcement Learning
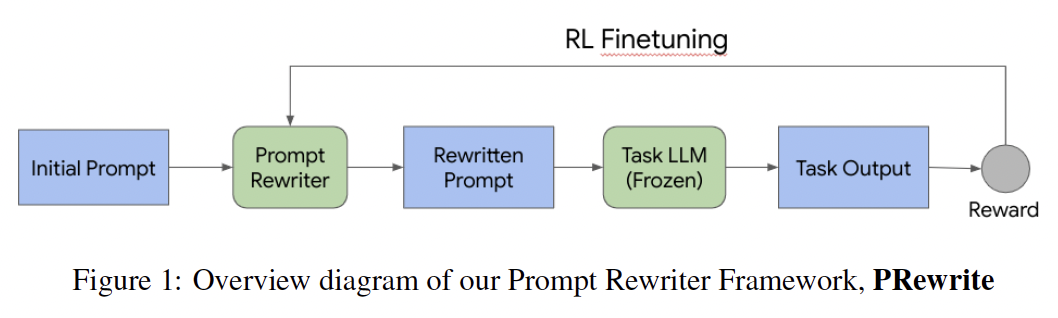
Prompt engineering is critical for the development of LLM-based applications. However, it is usually done manually in a “trial and error” fashion. This manual procedure can be time consuming, ineffective, and the generated prompts are, in a lot of cases, sub-optimal. Even for the prompts which seemingly work well, there is always a lingering question: can the prompts be made better with further modifications? To address these questions, in this paper, we investigate prompt engineering automation. We consider a specific use case scenario in which developers/users have drafted initial prompts, but lack the time/expertise to optimize them. We propose PRewrite, an automated tool to rewrite these drafts and to generate highly effective new prompts. PRewrite is based on the Reinforcement Learning (RL) framework which allows for end-to-end optimization and our design allows the RL search to happen in a large action space. The automated tool leverages manually crafted prompts as starting points which makes the rewriting procedure more guided and efficient. The generated prompts are human readable, and selfexplanatory, unlike some of those in previous works.
Introduction. With the wide-scale proliferation of LLMs, prompting LLMs has become critical to achieving desired results on various downstream tasks. With the right prompts, LLMs can show impressive performance on various downstream tasks in zero-shot or fewshot settings. Currently, most prompt engineering is done on an ad-hoc basis and there are no clear universal guidelines on writing good prompts for various downstream tasks. This approach is prone to various problems. Writing good prompts is timeconsuming and requires some amount of prior experience of working with LLMs to understand their performance and reasoning capabilities. It can also be ineffective as end-users who call the LLMs through APIs and even engineers might face difficulties in getting the LLMs to behave as intended through their hand-crafted prompts. Moreover, they might be sub-optimal as the manual prompts might not be optimized for the task at hand. To address the limitations above, we propose to automate the process of prompt engineering.
Discussion / Conclusion. In this paper, we presented our preliminary work on PRewrite, an automated prompt rewriter to improve the initial hand-crafted prompts using reinforcement learning. Our proposed method addresses the drawbacks of previous methods including using larger and more powerful models for the rewriting task, training the prompt rewriter end-to-end and producing human-readable prompts showing im- pressive performance over some of the previous SoTA models. As future work, we aim to test our approach on more diverse datasets and with larger models than the PaLM 2-S. We would also like to study the effectiveness of different meta-prompts and initial prompts on the task performance.