MemoChat: Tuning LLMs to Use Memos for Consistent Long-Range Open-Domain Conversation
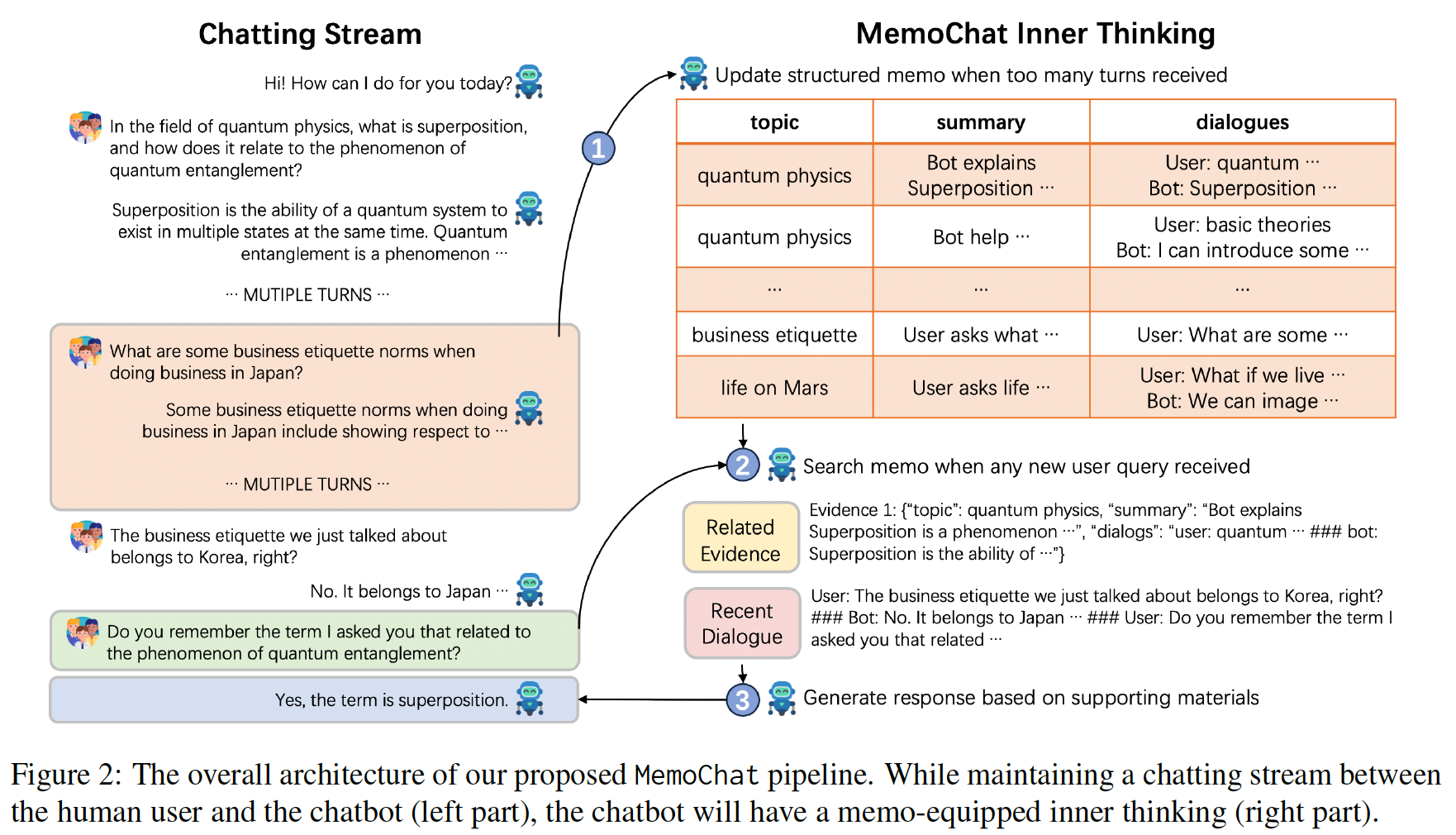
We propose MemoChat, a pipeline for refining instructions that enables large language models (LLMs) to effectively employ self-composed memos for maintaining consistent long-range open-domain conversations. We demonstrate a long-range open-domain conversation through iterative “memorization-retrieval-response” cycles. This requires us to carefully design tailored tuning instructions for each distinct stage. The instructions are reconstructed from a collection of public datasets to teach the LLMs to memorize and retrieve past dialogues with structured memos, leading to enhanced consistency when participating in future conversations. We invite experts to manually annotate a test set designed to evaluate the consistency of long-range conversations questions. Experiments on three testing scenarios involving both open-source and API-accessible chatbots at scale verify the efficacy of MemoChat, which outperforms strong baselines1.
Introduction. Large language models (LLMs) have brought about a substantial revolution, fundamentally changing our lifestyle. They have emerged as a new platform that connects the realms of academia and industry within the field of artificial intelligence (Zhao et al., 2023b; Yang et al., 2023). In particular, LLMs have demonstrated an enhanced ability to synchronize effectively with human cognitive processes (Du et al., 2022; Taori et al., 2023; Zheng et al., 2023; Liu et al., 2023c; Ouyang et al., 2022) and consequently have served as a foundation towards creating human-like conversational dialogues. In contrast to the traditional dialogue systems, which mainly involve short conversations on similar topics (Dinan et al., 2019b; Komeili et al., 2022; Dinan et al., 2019a), the emerging trend in humanchatbot interaction is characterized by longer conversations encompassing diverse topics (Kim et al., 2023). Figure 1 illustrates an example of such long-range conversations with more than 20 exchanges between a human user and a chat bot.
Discussion / Conclusion. We proposed MemoChat, an instruction tuning pipeline to teach LLMs to self-use on-the-fly structured memos towards consistent long-range open-domain conversations, which can be decomposed as “memorization-retrieval-response” loops. We carefully designed three trainable instructions based on public datasets for structured writing, fast retrieval, and interations with memos. An expertannotated downstream evaluation set was curated and provided. Experiments on three testing scenarios and various LLM-based chatbots demonstrated the effectiveness of MemoChat.