Improving Factuality and Reasoning in Language Models through Multiagent Debate
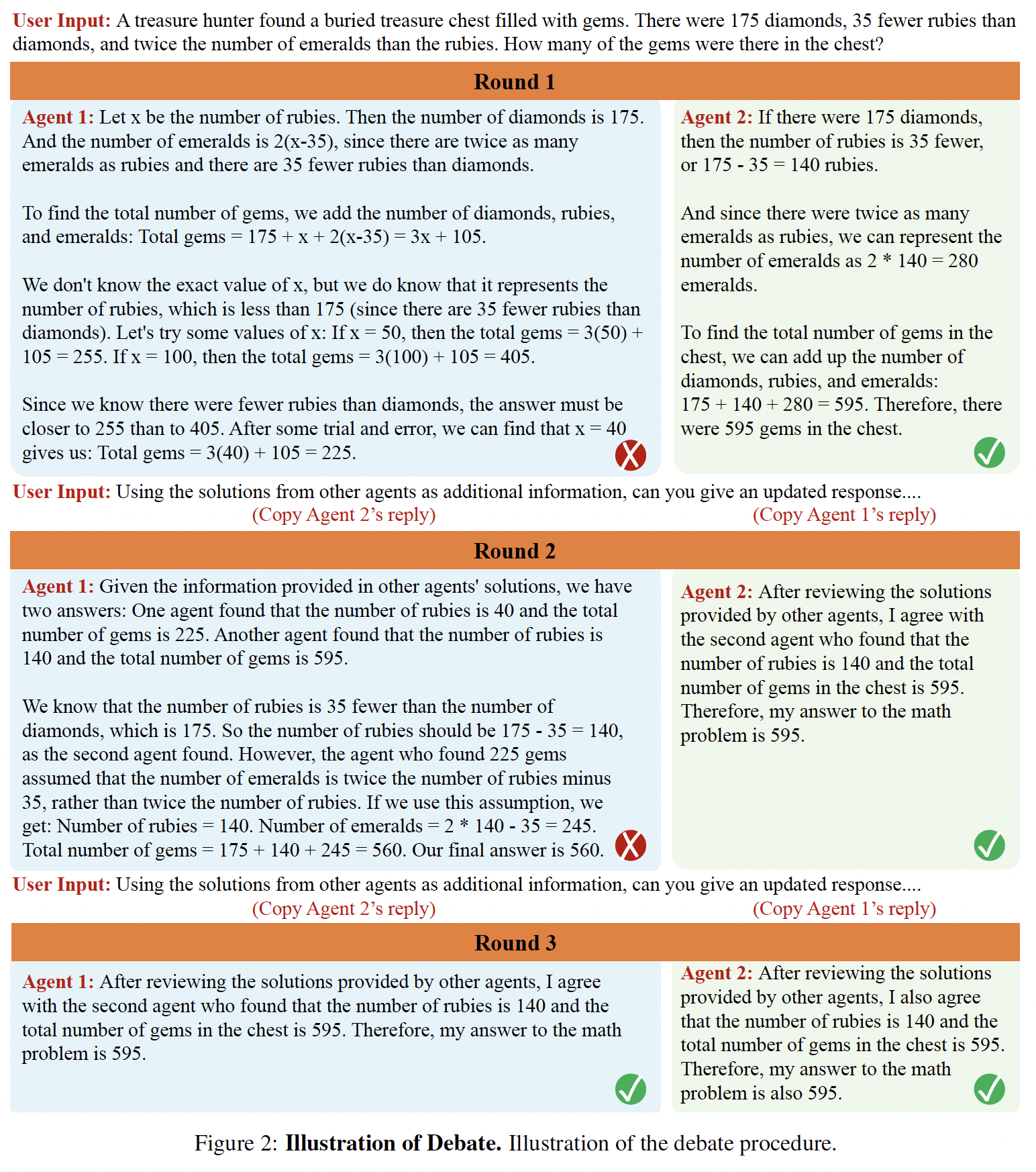
Large language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their performance may be further improved through the tools of prompting, ranging from verification, self-consistency, or intermediate scratchpads. In this paper, we present a complementary approach to improve language responses where multiple language model instances propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a common final answer. Our findings indicate that this approach significantly enhances mathematical and strategic reasoning across a number of tasks. We also demonstrate that our approach improves the factual validity of generated content, reducing fallacious answers and hallucinations that contemporary models are prone to. Our approach may be directly applied to existing black-box models and uses identical procedure and prompts for all tasks we investigate. Overall, our findings suggest that such "society of minds" approach has the potential to significantly advance the capabilities of LLMs and pave the way for further breakthroughs in language generation and understanding.
Introduction. Large language models (LLMs) have demonstrated remarkable language generation, understanding, and few-shot learning capabilities in recent years. These methods are trained on a massive corpus of text on the internet, where the quality and accuracy of extracted natural language may not be ensured. Thus, current models may suffer from confidently hallucinating facts or making implausible jumps in chains of reasoning. An extensive body of recent work has focused on improving factual accuracy and reasoning in language models. These range from prompting models with few or zero-shot chain-of-thought demonstrations, use of verification, self-consistency, or intermediate scratchpads.
Discussion / Conclusion. In this paper, we present an orthogonal approach to improve the performance of language models using multi-agent debate. We find that the approach is simple and effective across a wide set of different reasoning and validity language modeling tasks.