Prompted LLMs as Chatbot Modules for Long Open-domain Conversation
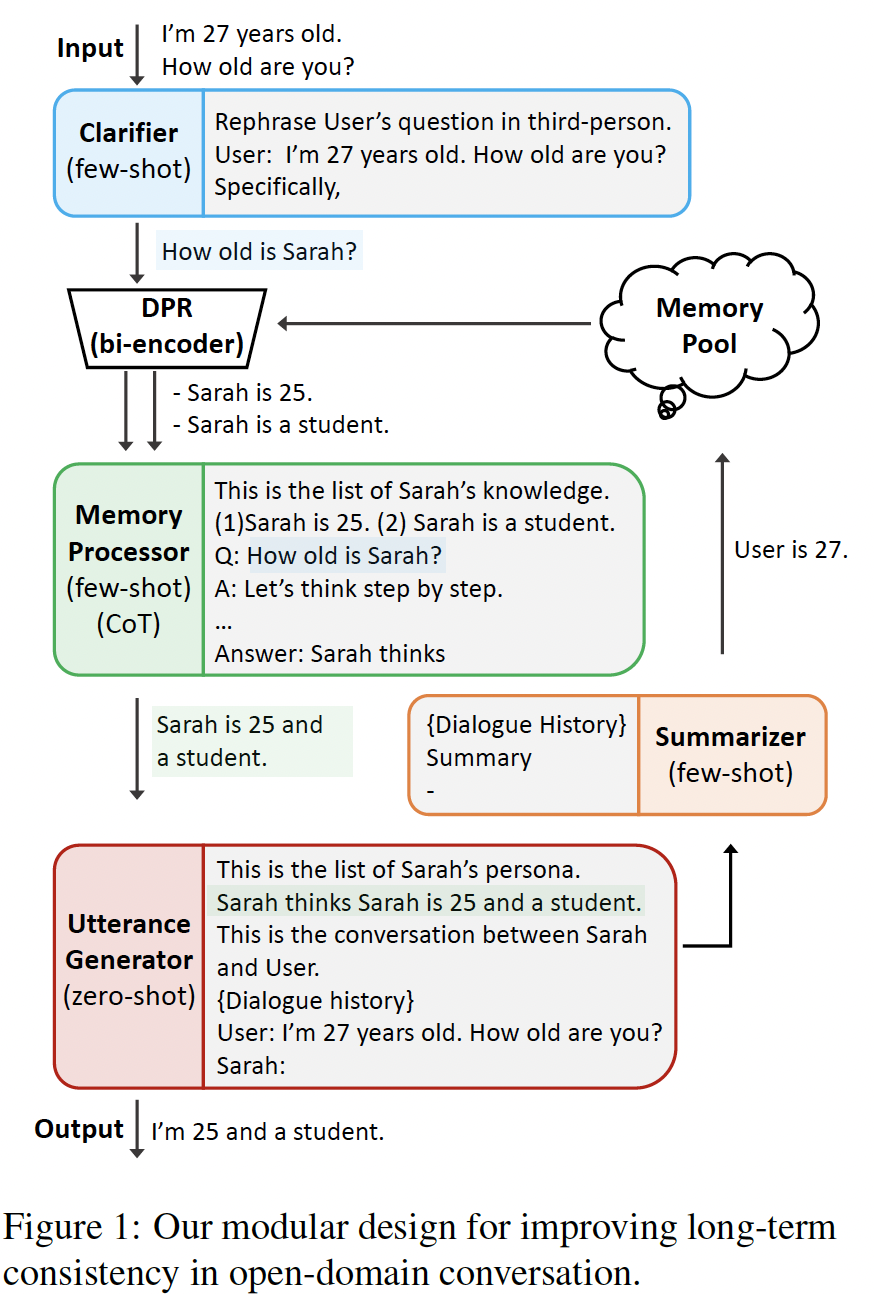
In this paper, we propose MPC (Modular Prompted Chatbot), a new approach for creating high-quality conversational agents without the need for fine-tuning. Our method utilizes pre-trained large language models (LLMs) as individual modules for long-term consistency and flexibility, by using techniques such as few-shot prompting, chain-of-thought (CoT), and external memory. Our human evaluation results show that MPC is on par with finetuned chatbot models in open-domain conversations, making it an effective solution for creating consistent and engaging chatbots.
Introduction. Language models with billions of parameters, such as GPT-3 (Brown et al., 2020) and PaLM (Chowdhery et al., 2022), have achieved state-of-the-art performance on many NLP tasks. To fine-tune these large language models (LLMs) for open-domain chatbot tasks, one could use a dataset of conversational data that is representative of the target domain. However, fine-tuning LLMs for opendomain chatbots can be challenging due to the computational burden of updating models with billions of parameters and the scarcity of data in the dialogue domain. Furthermore, fine-tuning can limit the model’s versatility by restricting it to a specific domain, and result in the loss of domainagnostic knowledge acquired during pre-training, as reported by Yang and Ma (2022). Multi-task training on different datasets, as proposed by Roller et al. (2021), can address the versatility issue but has limitations, such as the need for data to train each skill and the difficulty determining the necessary skills for an open-domain chatbot.
Discussion / Conclusion. We demonstrated that a modular approach using LLMs, namely MPC, can be an effective solution for long-term open-domain chatbots without further finetuning. We compared MPC to fine-tuned and vanilla LM baselines and found that our approach achieved superior performance by human evaluation. Additionally, our modular system incorporated persona and information from dialogue history more effectively than the non-modular ones according to our consistency evaluation. In this work, we investigate the use of pre-trained language models for long-term English conversations. While we expect a modular approach may be effective for other languages when given a capable language model, it should also be noted that further research is needed to confirm the applicability of our findings to other languages. For instance, though BLOOM is trained as a multilingual language model, we only implement MPCBLOOM in English and evaluate its English capability as a open-domain dialogue agent. Meanwhile, a modular system can create additional inference overhead or error accumulation. The system performance would become much better if we optimally choose the LM for each module. For example, we could use GPT-3 td2 for the memory processor, while we employ OPT-175B for the utterance generator.