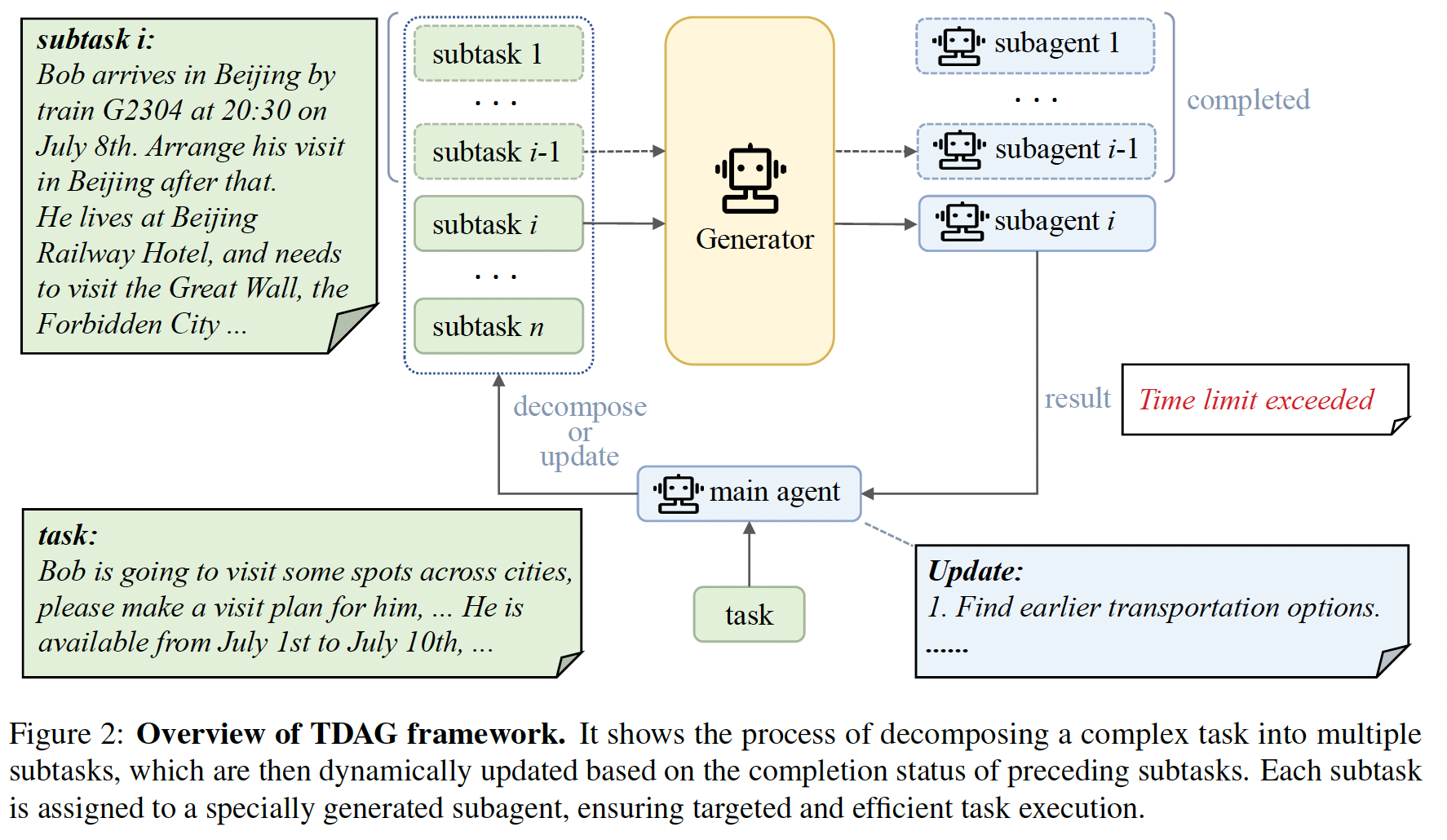
Reflexion: Language Agents with Verbal Reinforcement Learning
it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive model fine-tuning. We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback. Concretely, Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials. Reflexion is flexible enough to incorporate various types (scalar values or free-form language) and sources (external or internally simulated) of feedback signals, and obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). For example, Reflexion achieves a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4 that achieves 80%.
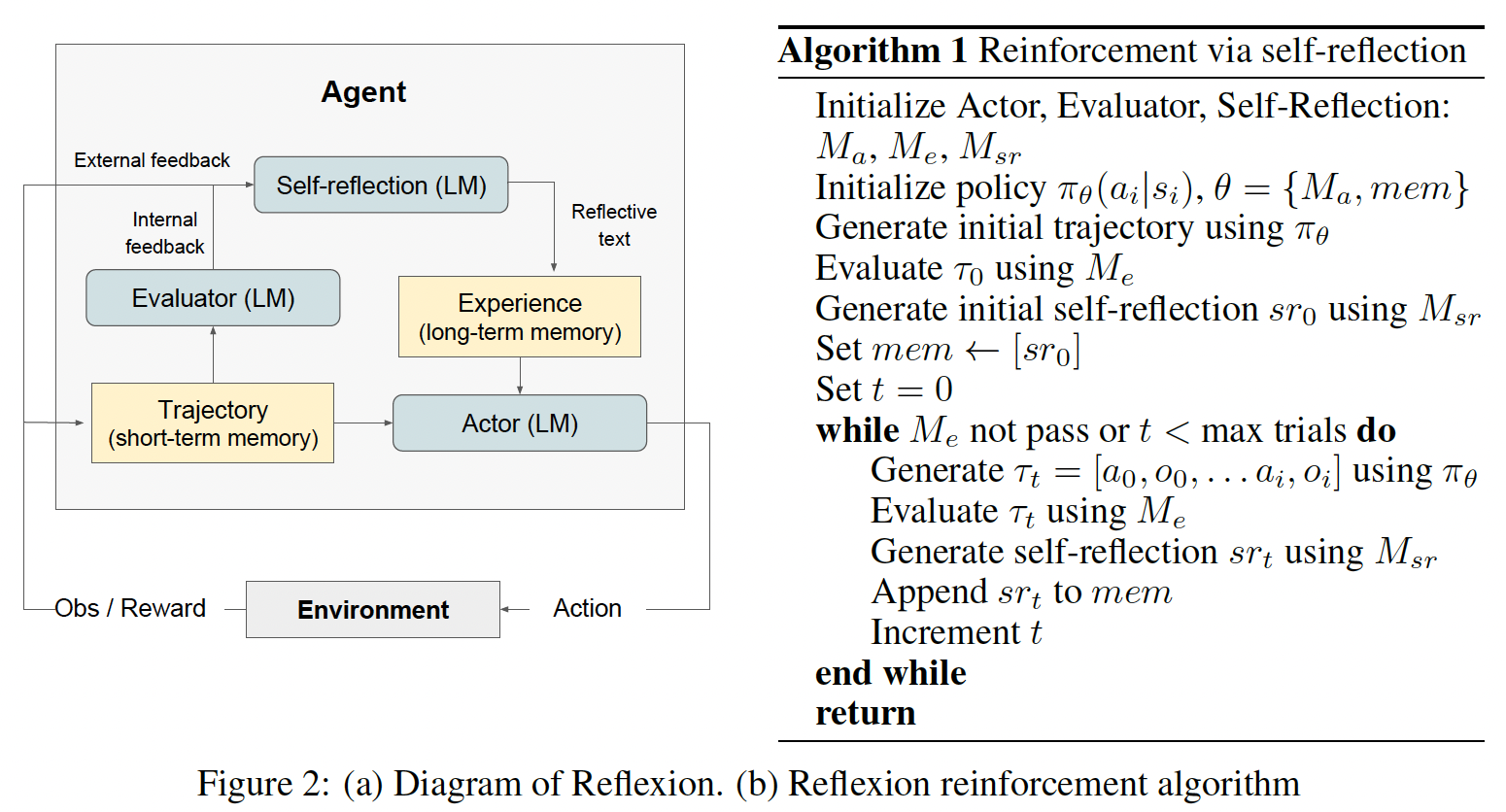

In this section, we introduce a multi-agent framework based on dynamic Task Decomposition and Agent Generation (TDAG), as illustrated in Figure 2. The framework is structured around two key components: (1) an advanced task decomposition strategy that dynamically adapts to the evolving requirements of complex tasks (Section 4.1), and (2) a flexible agent generation process that customizes agents for specific subtasks, enhancing adaptability and efficiency in varied scenarios (Section 4.2).
The main agent decomposes the task, and each subagent is assigned a subtask, the process of which is represented as
…
Note that each subagent focuses on a specific subtask, reducing the potential for noise of irrelevant information, thereby enhancing performance. Crucially, these decomposed subtasks are not static, but will be dynamically adjusted based on the outcomes of preceding tasks,