Rethinking with Retrieval: Faithful Large Language Model Inference
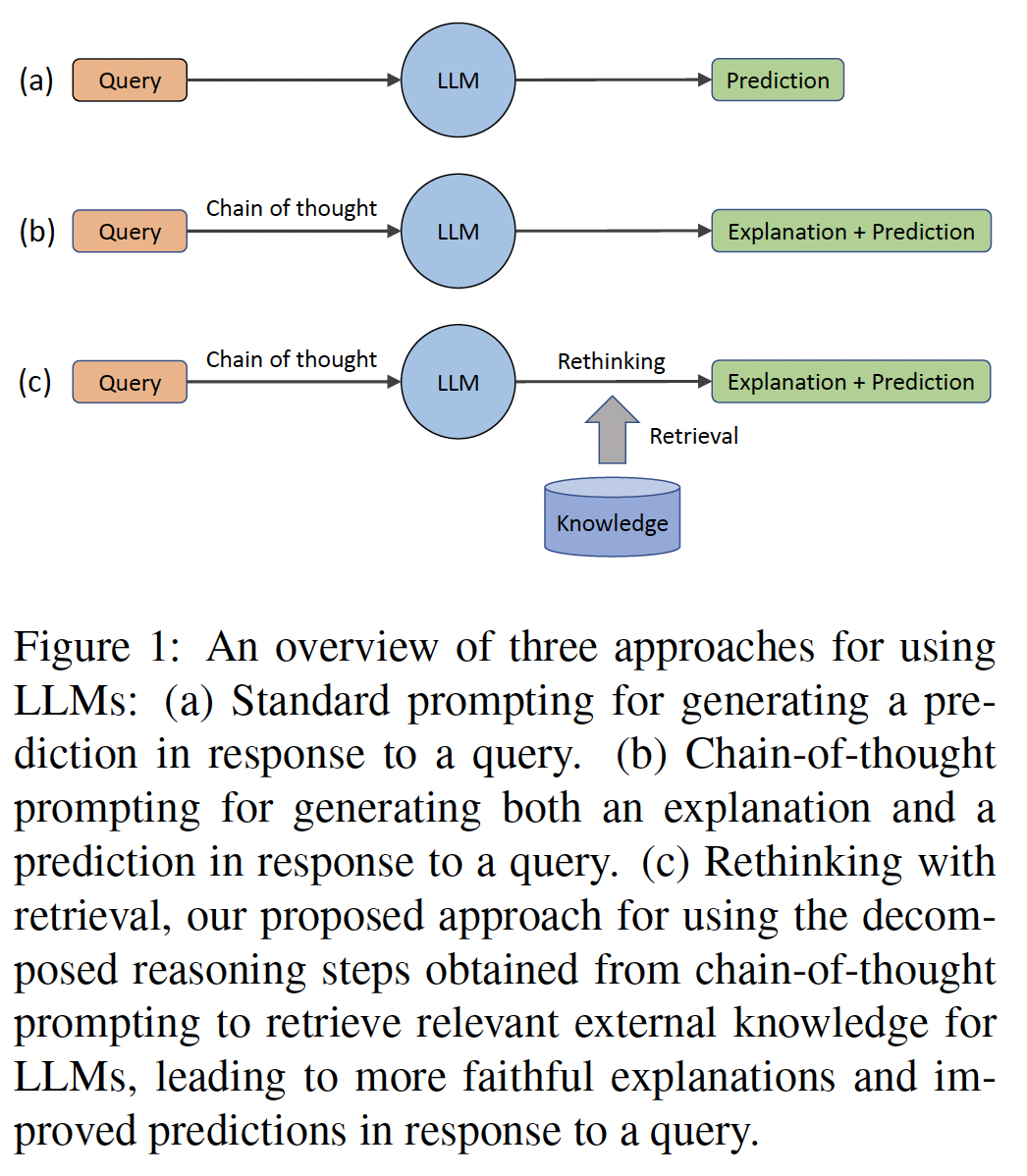
Despite the success of large language models (LLMs) in various natural language processing (NLP) tasks, the stored knowledge in these models may inevitably be incomplete, out-of-date, or incorrect. This motivates the need to utilize external knowledge to assist LLMs. Unfortunately, current methods for incorporating external knowledge often require additional training or fine-tuning, which can be costly and may not be feasible for LLMs. To address this issue, we propose a novel post-processing approach, rethinking with retrieval (RR), which retrieves relevant external knowledge based on the decomposed reasoning steps obtained from the chain-of-thought (CoT) prompting. This lightweight approach does not require additional training or fine-tuning and is not limited by the input length of LLMs. We evaluate the effectiveness of RR through extensive experiments with GPT-3 on three complex reasoning tasks: commonsense reasoning, temporal reasoning, and tabular reasoning. Our results show that RR can produce more faithful explanations and improve the performance of LLMs.1
Introduction. Large language models (LLMs) have shown exceptional performance across various tasks through in-context learning without task-specific training or fine-tuning (Brown et al., 2020; Chowdhery et al., 2022; Zhang et al., 2022; Ouyang et al., 2022). Recent progress in prompting (Wei et al., 2022; Zhou et al., 2022; Kojima et al., 2022) and decoding (Wang et al., 2022) has made it feasible for LLMs to tackle tasks that demand complex reasoning. However, the knowledge stored in LLMs might inevitably be incomplete, out-of-date, or incorrect. As a result, external sources of knowledge, such as Wikipedia, may be essential for the successful deployment of LLMs for real-world applications. Previously, people tried to utilize knowledge for smaller language models (LMs), such as T5 (Raffel et al., 2020), BERT (Devlin et al., 2019), and RoBERTa (Liu et al., 2019). However, these methods often require additional training or fine-tuning, which can be costly and thus impractical for LLMs.
Discussion / Conclusion. In conclusion, the proposed approach is a promising solution for utilizing external knowledge to assist LLMs. Unlike traditional methods, RR does not require additional training or fine-tuning, making it a lightweight and feasible option for LLMs. Through extensive experiments on three reasoning tasks using GPT-3, we have shown that RR is able to produce more faithful explanations and improve the performance of LLMs. In the future, we plan to investigate various variations of RR to enhance its effectiveness and efficiency in augmenting LLMs with external knowledge.