Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks
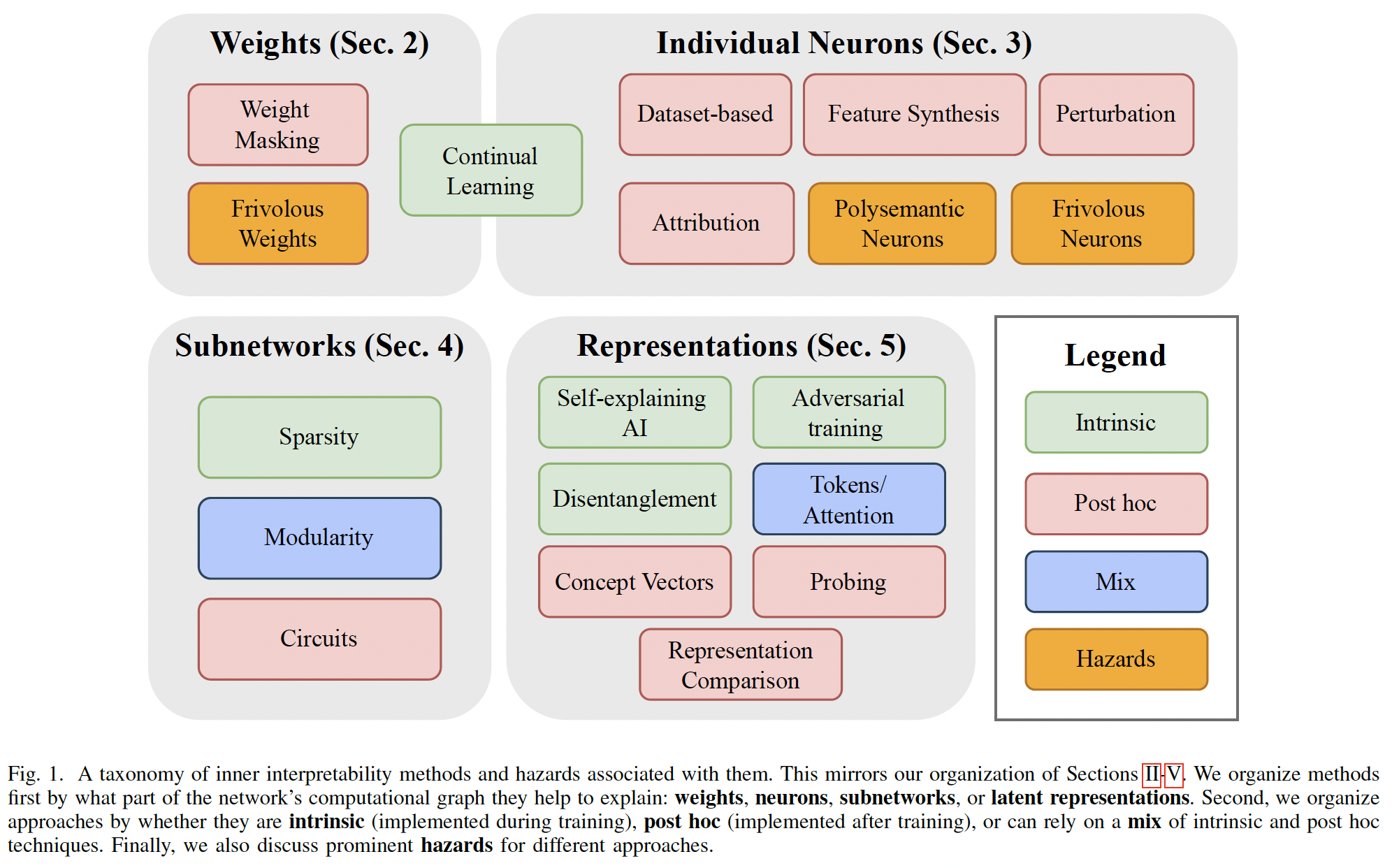
Abstract—The last decade of machine learning has seen drastic increases in scale and capabilities. Deep neural networks (DNNs) are increasingly being deployed in the real world. However, they are difficult to analyze, raising concerns about using them without a rigorous understanding of how they function. Effective tools for interpreting them will be important for building more trustworthy AI by helping to identify problems, fix bugs, and improve basic understanding. In particular, “inner” interpretability techniques, which focus on explaining the internal components of DNNs, are well-suited for developing a mechanistic understanding, guiding manual modifications, and reverse engineering solutions. Much recent work has focused on DNN interpretability, and rapid progress has thus far made a thorough systematization of methods difficult. In this survey, we review over 300 works with a focus on inner interpretability tools. We introduce a taxonomy that classifies methods by what part of the network they help to explain (weights, neurons, subnetworks, or latent representations) and whether they are implemented during (intrinsic) or after (post hoc) training.
Introduction. A defining feature of the last decade of deep learning is drastic increases in scale and capabilities [143], [264], with the training compute for machine learning systems growing by ten orders of magnitude from 2010 to 2022 [263]. At the same time, deep neural networks (DNNs) are increasingly being deployed in the real world. If rapid progress continues, broad-domain artificial intelligence could be highly impactful [39], [59], [209], [227], [246], [277]. Given this potential, it is important that practitioners can understand how AI systems make decisions, especially their issues. Models are most typically evaluated by their performance on a test set for a particular task. This raises concerns because a black box performing well on a test set does not imply that the learned solution is adequate. Testing sets typically fail to capture the full deployment distribution, including potential
Discussion / Conclusion. Interpretability is closely linked with adversarial robustness research. There are several connections between the two areas, including some results from non-inner interpretability research. (1) More interpretable DNNs are more robust to adversaries [141]. A number of works have studied this connection by regularizing the input gradients of networks to improve robustness [37], [80], [90], [97], [120], [144], [147], [192], [218], [241], [258]. Aside from this, [82] use lateral inhibition, and [281] use a second-order optimization technique, each to improve both interpretability and robustness. Furthermore, emulating properties of the human visual system in a convolutional neural network improves robustness [70]. (2) More robust networks are more interpretable [19], [86], [88], [228]. Adversarially trained networks also produce better representations for transfer learning [7], [253], image generation [49], [51], [256], modeling the human visual system [89], and fitting symbolic graphs [239]. (3) Interpretability tools can be used to design adversaries. Doing so is a way to rigorously demonstrate the usefulness of the interpretability tool.