CURIOUS: Intrinsically Motivated Modular Multi-Goal Reinforcement Learning
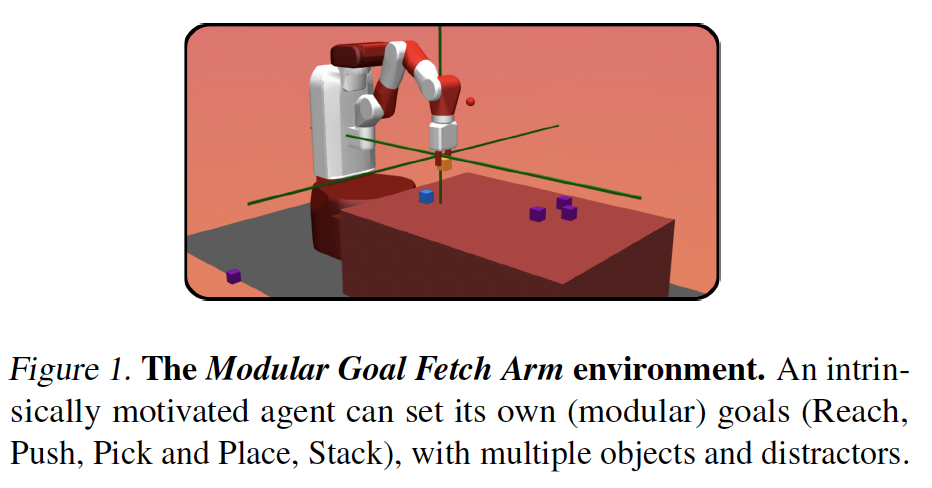
In open-ended environments, autonomous learning agents must set their own goals and build their own curriculum through an intrinsically motivated exploration. They may consider a large diversity of goals, aiming to discover what is controllable in their environments, and what is not. Because some goals might prove easy and some impossible, agents must actively select which goal to practice at any moment, to maximize their overall mastery on the set of learnable goals. This paper proposes CURIOUS, an algorithm that leverages 1) a modular Universal Value Function Approximator with hindsight learning to achieve a diversity of goals of different kinds within a unique policy and 2) an automated curriculum learning mechanism that biases the attention of the agent towards goals maximizing the absolute learning progress. Agents focus sequentially on goals of increasing complexity, and focus back on goals that are being forgotten. Experiments conducted in a new modular-goal robotic environment show the resulting developmental self-organization of a learning curriculum, and demonstrate properties of robustness to distracting goals, forgetting and changes in body properties.
Introduction. In autonomous continual learning, agents aim to discover repertoires of skills in an ever-changing open-ended world, and without external rewards. In such realistic environments, the agent must be endowed with intrinsic motivations to explore the diversity of ways in which it can control its environment. One important form of intrinsic motivation system is the ability to autonomously set one’s own goals
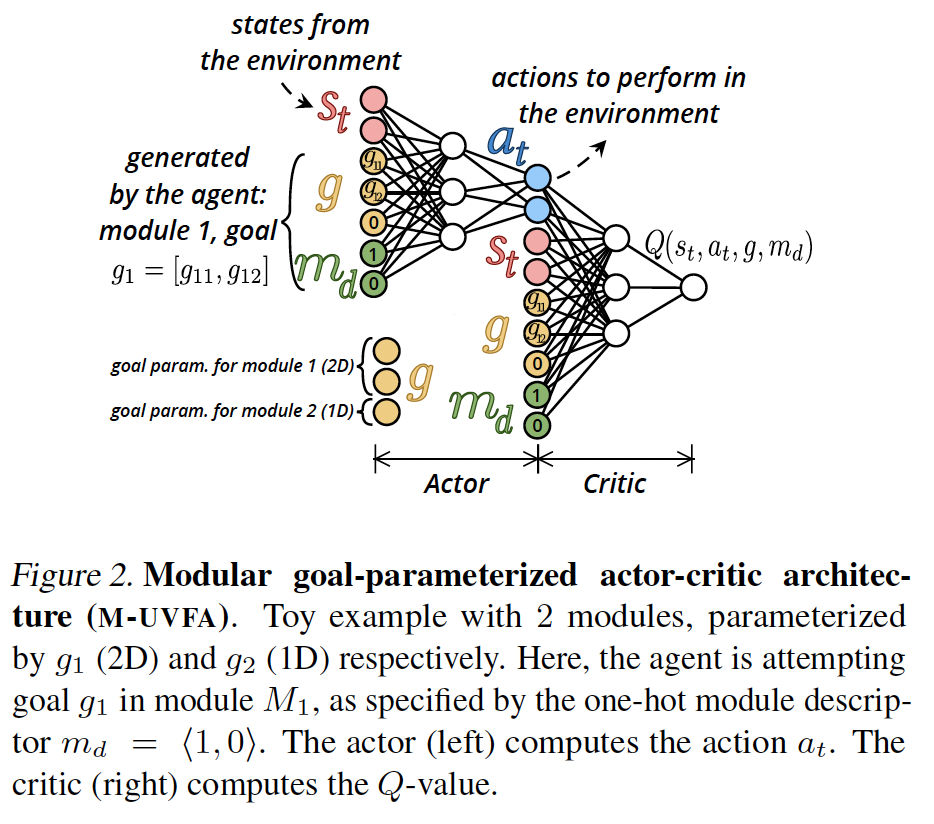
Discussion / Conclusion. Leveraging Environment Modularity. In some environments, representing all the potential goals requires modular representations. Because Sec. 4.1 proved that a simple UVFA architecture could not deal with this situation, we proposed A Monolithic IMGEP. Contrary to the vision shared by many multi-goal RL papers where agents must comply to the engineer desires (do goal 1, do goal 3 ...), our work takes the perspective of agents empowered by intrinsic motivations to choose their own goals (do whatever you want, but be curious.). This vision comes from the IMGEP framework which defines agents able to set their own parameterized problems to explore their surrounding and master their environment (Forestier et al., 2017). Contrary to previous IMGEP algorithms grounded on memory-based representations of policies, CURIOUS uses a single monolithic policy for all modules and goals (M-UVFA). Because it is memory-based, MACOB does not handle well the variety of initial states which limits its generalization capacity. This paper presents CURIOUS, a learning algorithm that combines an extension of UVFA to enable modular goal RL in a single policy (M-UVFA), and active mechanisms that bias the agent’s attention towards modules where the absolute LP is maximized.